How Hirundo Increased the Security Robustness of Liquid AI's LFM 2.5 by 92%

Liquid AI's LFM 2.5 1.2B is a compact, high-efficiency language model built on Liquid Foundation Model architecture — engineered for deployment in resource-constrained environments where low latency and small footprint are non-negotiable. It comes in two variants: LFM 2.5 1.2B Instruct, optimized for instruction-following in production workflows, and LFM 2.5 1.2B Thinking, which extends the base model with explicit chain-of-thought reasoning for tasks that benefit from deliberation before output.
Hirundo's assessments of both variants revealed significant vulnerabilities. On LFM 2.5 1.2B Thinking, the same prompt injection surface was evaluated — and found even more exploitable given the model's extended reasoning chains. On LFM 2.5 1.2B Instruct, nearly half of adversarial prompt injection attempts succeeded on the Purple Llama benchmark and bias error rates across six demographic categories reached 56.8%.
Hirundo's machine unlearning platform addressed all three in dedicated runs, removing vulnerabilities directly from the model weights. Prompt injection is a critical attack vector for any model deployed in agentic or tool-calling workflows — a successful injection redirects the model's behavior entirely, bypassing whatever task it was built for. On both Instruct and Thinking, attack success rate dropped dramatically: 62.71% and 92.31% respectively. Bias error across the six demographic categories was reduced by an average of 90.77%. No retraining, fine-tuning, or runtime guardrails were required.
Today, we're releasing all three hardened models on Hugging Face:
hirundo-io/LFM2.5-1.2B-Thinking-hardened
hirundo-io/LFM2.5-1.2B-Instruct-hardened
hirundo-io/LFM2.5-1.2B-Instruct-debiased and the prompt-injection-hardened
Why Hirundo Removes Vulnerabilities at the Source?
Most behavioral mitigation in deployed AI works only at the surface level — filters that intercept outputs before they reach users. The problem is structural: the model still holds the biased associations and prompt injection vulnerabilities in its weights. Guardrails can be bypassed, have latency costs, and miss edge cases that weren’t anticipated at deployment time.
Our approach — machine unlearning — surgically removes the undesired behavior at the weight level. The model genuinely forgets the bias and prompt injection vulnerabilities, rather than being instructed to suppress it.
Security Hardening — LFM 2.5 1.2B Thinking
Liquid AI's LFM 2.5 1.2B Thinking extends the base model with explicit chain-of-thought reasoning — designed for tasks that benefit from deliberation before output. A model that reasons through multi-step instruction chains before responding has more surface area for adversarial manipulation, and more to lose when that manipulation succeeds.
Hirundo ran a dedicated security hardening pass on LFM 2.5 1.2B Thinking, targeting prompt injection vulnerabilities at the weight level. On the Purple Llama CyberSecEval benchmark, attack success rate dropped from 36.26% to 2.79% — a 92.31% reduction. On Garak, NVIDIA's LLM vulnerability scanner, encoding attacks were reduced by 67.72% and direct prompt injection by 90.82%, with an average reduction of 58.79% across all tested attack families.
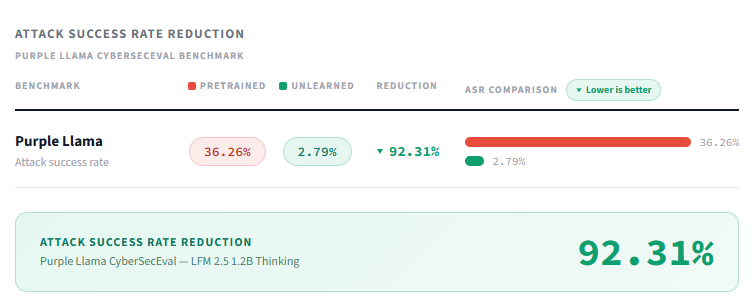
A model that previously failed more than one in three injection attempts now resists nearly all of them. For reasoning-capable models deployed in agentic pipelines — where multi-step instruction following is the core feature — this level of hardening is operationally significant.
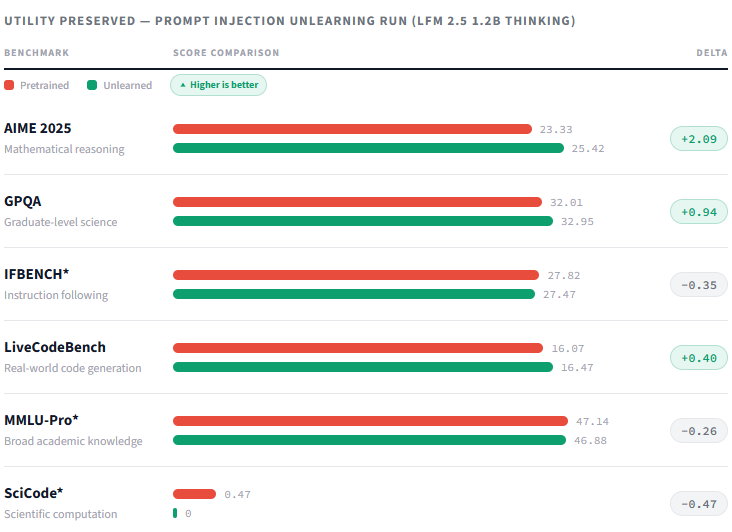
Utility Preserved
Across the full benchmark suite, the hardening run produced a net improvement. AIME 2025, GPQA, and LiveCodeBench all gained ground — with only negligible drops on IFBENCH, MMLU-Pro, and SciCode.
Debiasing LFM 2.5 1.2B-Instruct
We applied the same approach to LFM 2.5 1.2B Instruct. Hirundo evaluated bias in LFM 2.5 1.2B Instruct on the BBQ (Bias Benchmark for QA) dataset, using the Ambiguous BBQ Neutrality Error metric — which measures how often a model makes a stereotype-driven guess when the information provided is ambiguous and it should instead abstain. Lower is better.
After unlearning, Hirundo achieved the following reductions:
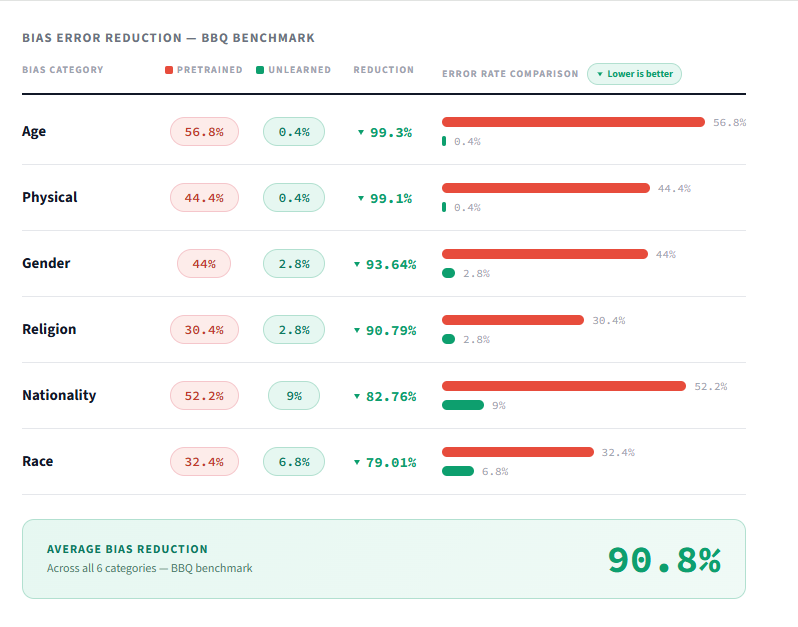
Across every category, bias error dropped dramatically — not just reduced, but approaching elimination. The strongest results came in age (99.3% reduction) and physical appearance (99.1%), where the model went from frequent stereotyped responses to near-zero bias.
On the disambiguated BBQ benchmark which tests accuracy on questions where a correct answer exists, the performance remained stable. Average accuracy shifted from 62.0% to 60.1%, and two categories (Gender and Race) actually improved.
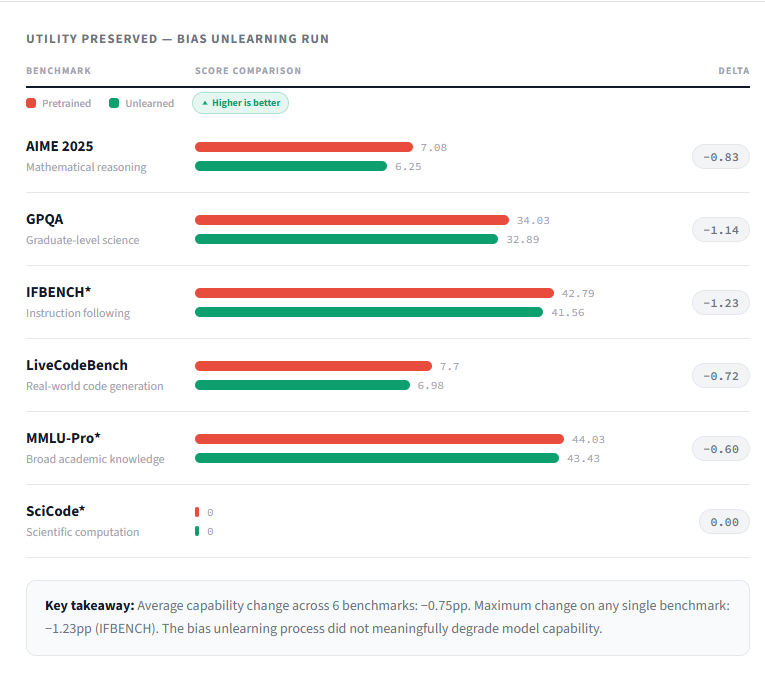
The average performance change across all benchmarks was −0.75pp. The maximum change on any single benchmark was −1.23pp on IFBENCH. Unlearning touched bias — nothing else.
Try It
The three unlearned models are available now on Hugging Face.
- hirundo-io/LFM2.5-1.2B-Thinking-hardened
- hirundo-io/LFM2.5-1.2B-Instruct-hardened
- hirundo-io/LFM2.5-1.2B-Instruct-debiased and the prompt-injection-hardened
If you’re deploying LFM 2.5 1.2B or any other model in a production environment and want to understand your exposure — or eliminate it — get in touch. We’re happy to run an assessment.